



In-depth internal linking can sometimes be laborious and time-consuming. I wanted to create a Python script that would help with internal linking providing potential opportunities while having a low-time impact. This is by no means a single solution to internal linking however it's always nice to have multiple tools in your arsenal.
What does the script do?
The key concept of the script is to provide it with a list of keywords that would be useful internal anchors to pages that you believe need more internal links. You will then want to provide a list of URLs (this could be gathered from Screaming Frog etc).
The URLs provided will then be crawled and the content within these pages will be collected and cross referenced with your list of keywords. Any pages that contain one of the keywords you provide will be saved to an excel document for further investigation.
An example of this can be seen below:
How to use the script
You will want to create a excel document named "from.xlsx". This will be your main input file. You will need to enter all of your websites URLs (or atleast the ones you want to check) into column A. Column B will be used for listing all keywords that you want to check for.
The order of these URLs and keywords doesn't matter so you can put them in freely.
When you run the script, the script will reference this file so close it before running just to avoid any potential issues. After letting the script run, it will create a file named "InternalFinds", this file will contain everything you need to review the internal linking opporunities.
Building the Internal Linking Opportunity Script
This is one of the first scripts I made so it's far from the most optimised it could be, and if anyone decides to optimise it please let me know.
Libraries
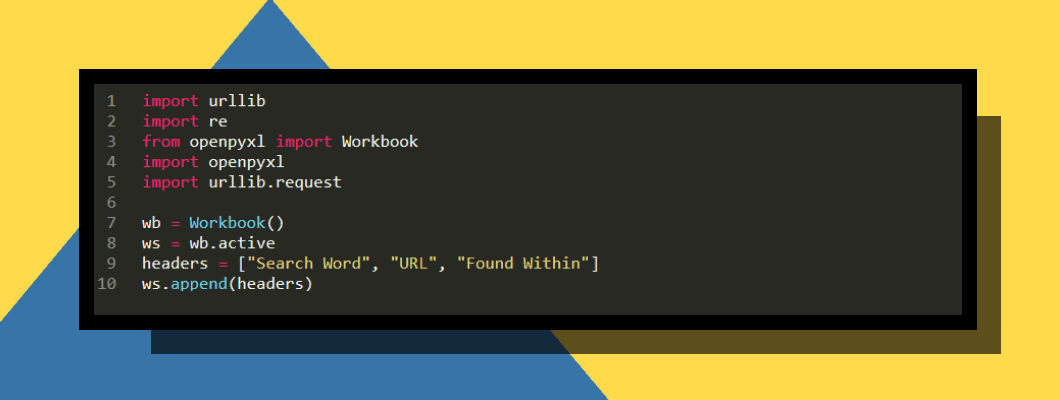
We will be using multiple Libraries in this script to scrape URLs, and deal with saving the data to excel. You will want to use the below imports at the start of your python file:
import urllib
import re
from openpyxl import Workbook
import openpyxl
import urllib.request
A quick definition of what these imports do:
- urlib - This library is what we use to query URL and parse HTML data
- openpyxl - This library deals with connecting the script to excel to read and save data
Gathering Content
We will now want a way to crawl each URL provided and store the content related to each URL. The below snippet of code is a function that takes in the URL as a parameter, requests that page, parses it's HTML and stores what we regard as content in an array.
When I originally created this I tried to make it somewhat universal by defining content may be in a <main> tag, you can see nested try/except statements that attempt to find the best case scenario, you may want to adjust this to accommodate your own websites build. That being said, if it can't find content in a <main> tag, then it will just gather all content within <p> tags.
def content_get(turl):
contentArray = []
req = urllib.request.Request(turl, headers={'User-Agent': 'Mozilla/5.0'})
html = urllib.request.urlopen(req).read().decode("utf-8").lower()
soup = BeautifulSoup(html, 'html.parser')
try:
try:
try:
texts = soup.find('main','main')
bottom = texts.find_all('p')
except:
texts = soup.find('div','main')
bottom = texts.find_all('p')
except:
texts = soup.find('main')
bottom = texts.find_all('p')
except:
bottom = soup.find_all('p')
for b in bottom:
textParaOne = b.getText()
paraOne = re.sub(r'[^A-Za-z0-9 ]+', '', textParaOne)
contentArray.append(paraOne)
content = list(filter(None, contentArray))
return content
Working with Excel
We will now want a way for the script to sort the data provided by us in excel. The below snippet of code was created to create an excel document that we will save anything we find in. As well as looping through all the data we provided and saving this data in their respective arrays.
wb = Workbook()
ws = wb.active
headers = ["Search Word", "URL", "Found Within", "Found Within Trim"]
ws.append(headers)
number = 1
book = openpyxl.load_workbook('from.xlsx')
openbook = book.active
aCount = 0
bCount = 0
urllist = []
keywordlist = []
## Count URLs ##
for row in openbook['A']:
a = row.value
if a == None:
pass
if a != None:
aCount = aCount + 1
urllist.append(a)
## Count Keywords ##
for row in openbook['B']:
b = row.value
if b == None:
pass
if b != None:
bCount = bCount + 1
keywordlist.append(b)
Collecting Content
We will now want to collect the content using the function we created earlier. We will be storing this data in an 2d array so that a URL is grouped with its content.
contentList = []
leng = len(urllist)
for url in urllist:
print(str(number) + "/" + str(leng))
number = number + 1
urlof = url
urlcontent = content_get(url)
contentList.append((urlof,urlcontent))
Finding Opportunities and Storing them
This is the final section of the script that uses the data we have sorted to loop through each itteration and find any opportunities where a keyword has been mentioned somewhere thing the content.
We will then be outputting the content into our excel file, this is list the URL the opportunity was found on along with the keyword. We also want to provide a section of the paragraph the keyword was found in, this will make it easier to narrow down the area on the webpage we want to look at.
numberHead = 2
for keyword in keywordlist:
print("Finding: " + keyword)
for contentFind in contentList:
content = contentFind[1]
contenturl = contentFind[0]
for cont in content:
if len(re.findall("\\b" + keyword + "\\b", cont)) > 0:
ws['A' + str(numberHead)] = keyword
ws['B' + str(numberHead)] = contenturl
ws['C' + str(numberHead)] = cont
ws['D' + str(numberHead)] = "=trim(C" + str(numberHead) + ")"
numberHead = numberHead + 1
else:
pass
wb.save(filename = 'InternalFinds.xlsx')
Final Code
import urllib
import re
from openpyxl import Workbook
import openpyxl
import urllib.request
wb = Workbook()
ws = wb.active
headers = ["Search Word", "URL", "Found Within", "Found Within Trim"]
ws.append(headers)
number = 1
def content_get(turl):
contentArray = []
req = urllib.request.Request(turl, headers={'User-Agent': 'Mozilla/5.0'})
html = urllib.request.urlopen(req).read().decode("utf-8").lower()
soup = BeautifulSoup(html, 'html.parser')
try:
try:
try:
texts = soup.find('main','main')
bottom = texts.find_all('p')
except:
texts = soup.find('div','main')
bottom = texts.find_all('p')
except:
texts = soup.find('main')
bottom = texts.find_all('p')
except:
bottom = soup.find_all('p')
for b in bottom:
textParaOne = b.getText()
paraOne = re.sub(r'[^A-Za-z0-9 ]+', '', textParaOne)
contentArray.append(paraOne)
content = list(filter(None, contentArray))
return content
book = openpyxl.load_workbook('from.xlsx')
openbook = book.active
aCount = 0
bCount = 0
urllist = []
keywordlist = []
for row in openbook['A']:
a = row.value
if a == None:
pass
if a != None:
aCount = aCount + 1
urllist.append(a)
for row in openbook['B']:
b = row.value
if b == None:
pass
if b != None:
bCount = bCount + 1
keywordlist.append(b)
contentList = []
leng = len(urllist)
for url in urllist:
print(str(number) + "/" + str(leng))
number = number + 1
urlof = url
urlcontent = content_get(url)
contentList.append((urlof,urlcontent))
numberHead = 2
for keyword in keywordlist:
print("Finding: " + keyword)
for contentFind in contentList:
content = contentFind[1]
contenturl = contentFind[0]
for cont in content:
if len(re.findall("\\b" + keyword + "\\b", cont)) > 0:
ws['A' + str(numberHead)] = keyword
ws['B' + str(numberHead)] = contenturl
ws['C' + str(numberHead)] = cont
ws['D' + str(numberHead)] = "=trim(C" + str(numberHead) + ")"
numberHead = numberHead + 1
else:
pass
wb.save(filename = 'InternalFinds.xlsx')